使用AWS Lambda中的层(Layer)解决依赖库的问题
在前面分享了如何使用Serverless Requirements在AWS无服务器架构中配置Python依赖库,但这种做法的缺点就是在每个Lamda项目中都需要配置依赖库。这样每次生成的Lambda都包含了对应的依赖库,因此文件会很大。在每次部署的时候耗时更长,同时占用很多S3存储资源,可以说既费时又费钱。同样,这种方法的重用性非常差,因此我们希望通过一种可以重用的方式,只将依赖库保存一份,每当在需要时引用一下就可以了。这就是下面要介绍的AWS Lambda中的层(Layer)。

层的使用就类似于在各种编程语言中使用程序库一样,只需引用就可以在不同程序中使用共享的程序库,而无需将程序库部署到Lambda中。使用Lambda中的的层有以下优点:
- 这种依赖库是可以在不同的Lambda中共享的。这样在每次使用这些常用的依赖库时只需在Lambda中添加对这个层的引用就可以了。这样就可以节省费用,提高开发速度。
- 通过这种方式可以有效减少Lambda函数的大小,从而可以在Lambda控制台中直接调试代码。
- Lambda中的层支持Python, Node.js, Ruby等主流开发语言。
- 可以在不同AWS账号之间共享层。
下面以一个非常简单的Lambda来说明如何使用层来进行开发:
首先,创建一个非常简单的Lambda,这里我们不用Serverless框架,直接在Lambda控制台中创建如下的Lambda函数:
import json
import xmltodict
def lambda_handler(event, context):
xml='''<user>
<name>aafeng</name>
<url>https://www.aafeng.uk</url>
</user>'''
return {
"statusCode": 200,
"user": json.dumps(xmltodict.parse(xml))
}
很显然,由于找不到xmltodict这个依赖库,这个Lambda函数无法正常运行:
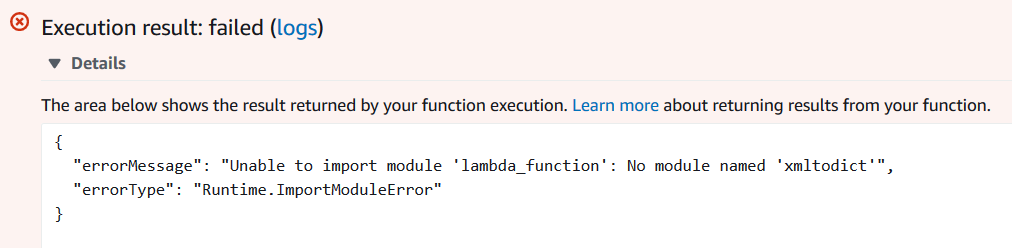
下面我们就将xmltodict打包并创建一个层,并在Lambda中添加对这个层的引用来解决上面的这个问题。
运行如下命令创建一个包含xmltodict依赖库的zip文件:
mkdir -p layer/python
cd layer
pip install xmltodict -t python
zip -r ../xmltodict.zip .
然后可以看到生成了xmltodict.zip这个文件。
在AWS中通过上传刚生成的xmltodict.zip来创建一个层。记录下这个层的id: arn:aws:lambda:eu-west-1:xxxxxxxxxxxxxx:layer:xmltodict:1
回到AWS Lambda控制台,单击“Add Layer”,将刚创建的层添加后再次运行这个Lambda函数,可以看到已经没有问题了。
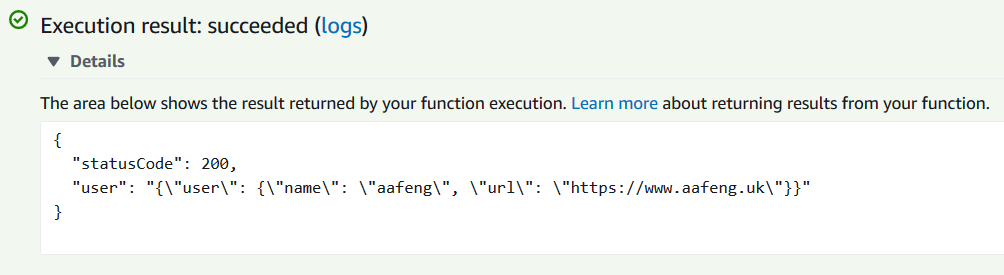
从层的执行机制上来说,其实在Lambda运行时,层会被提取到/opt目录,Lambda的运行时会在该目录下查找对应的库。
但使用层的时候也是有限制的。比如:每个Lambda中最多使用5个层,Lambda+各个使用到的层的总大小不能超过250MB。但对于一般引用来说是足够了。如果超出这个大小,说明你的Lambda干的活太多了,需要再进行拆分。









Comments