How to save Hive posts into Elasticsearch
Elasticsearch is a great search engine providing a distributed, multitenant-capable full-text search. It provides features like facets, keyword highlighting etc in the search user interface. Here is a tutorial to index Hive posts into elasticsearch.

Install Elasticsearch
Download Elasticsearch(ES) from the official site:
https://www.elastic.co/cn/downloads/elasticsearch
Decompress:
tar xvf elasticsearch-7.7.0-linux-x86_64.tar.gz
Then run the following command to start ES:
cd elasticsearch-7.7.0/bin
./elasticsearch
Use curl to test:
curl localhost:9200
You will the the output like:
{
"name" : "YOUR_SERVER_NAME",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "liHA066AQJeE91lv8lLqig",
"version" : {
"number" : "7.7.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "81a1e9eda8e6183f5237786246f6dced26a10eaf",
"build_date" : "2020-05-12T02:01:37.602180Z",
"build_snapshot" : false,
"lucene_version" : "8.5.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
Install Kibana
You don’t have to install Kibana prior to using ES. However, Kibana provides lots of additional features to your data.
Download from: https://www.elastic.co/cn/downloads/kibana
Decompress and modify file: config/kibana.yml, add this line:
server.host: "0.0.0.0"
Run Kibana
cd bin
./kibana
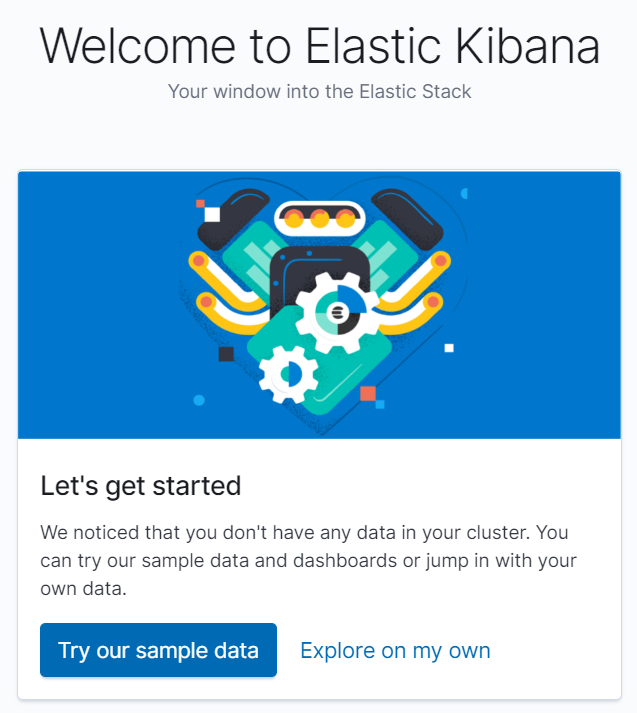
You will see the following UI
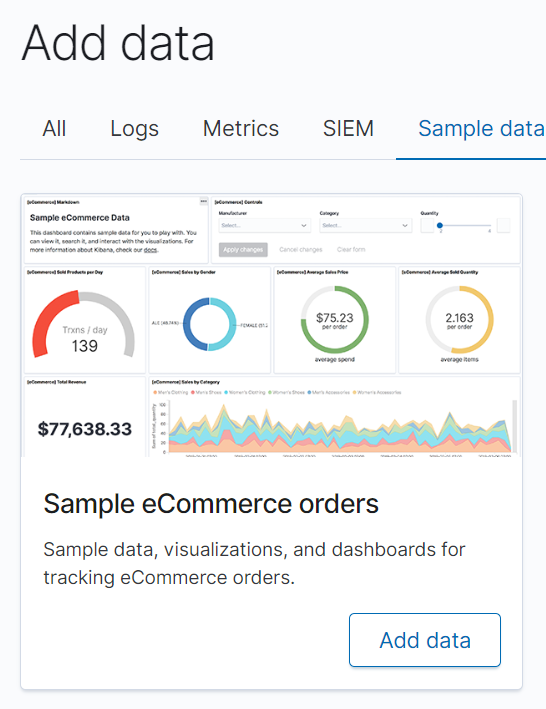
Import the eCommerence data for testing:
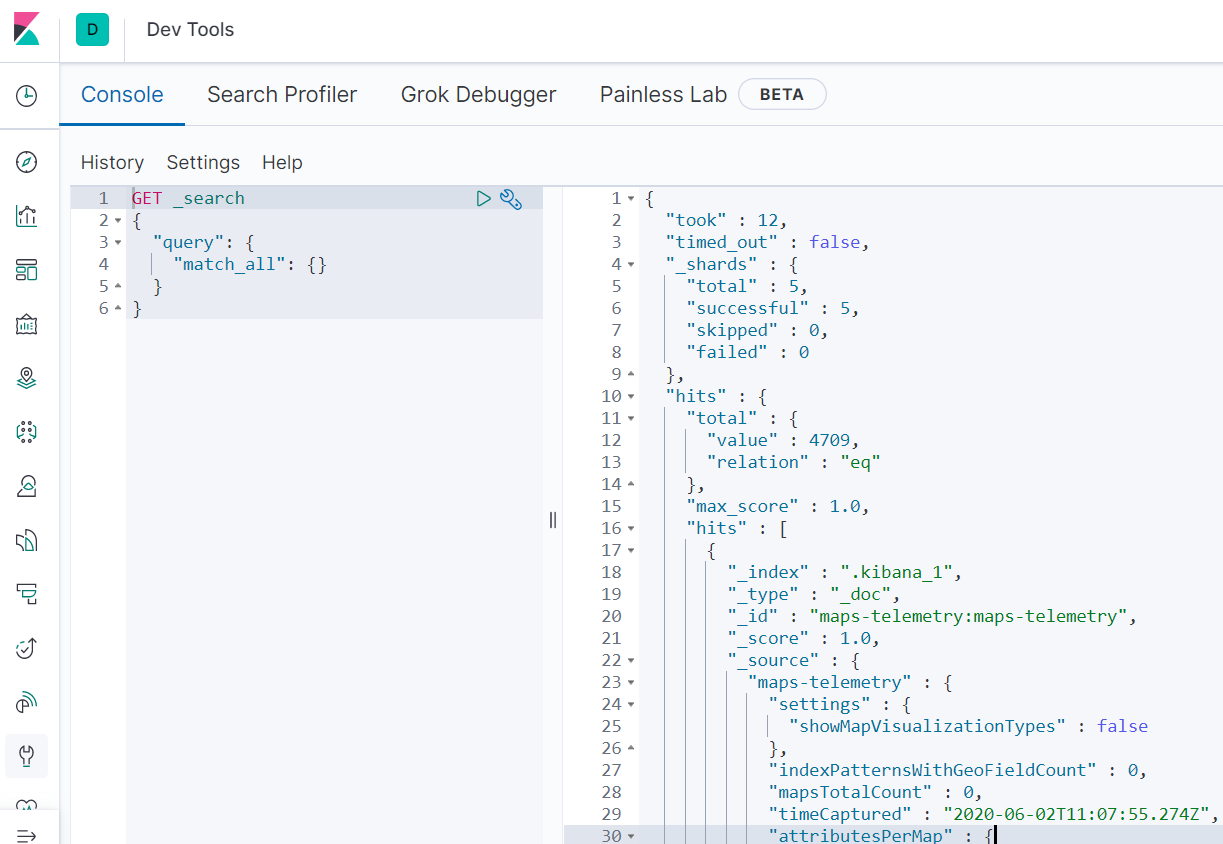
Open the devtool and run a simple query, you will see:
Important concepts in ES
Let’s compare the terms in ES with relational database:
ES RDB
Index => Database
Type => Table
Document => Row
Field => Column
Mapping => Schema
Install and test Python elasticsearch module
Install elasticsearch via pip:
pip install elasticsearch
Enter Python interactive mode, and run the following commands to create ES index called “hive-posts-index”:
>>> from datetime import datetime
>>> from elasticsearch import Elasticsearch
>>> es = Elasticsearch()
>>> es.indices.create(index='hive-posts-index', ignore=400)
{'acknowledged': True, 'shards_acknowledged': True, 'index': 'hive-posts-index'}
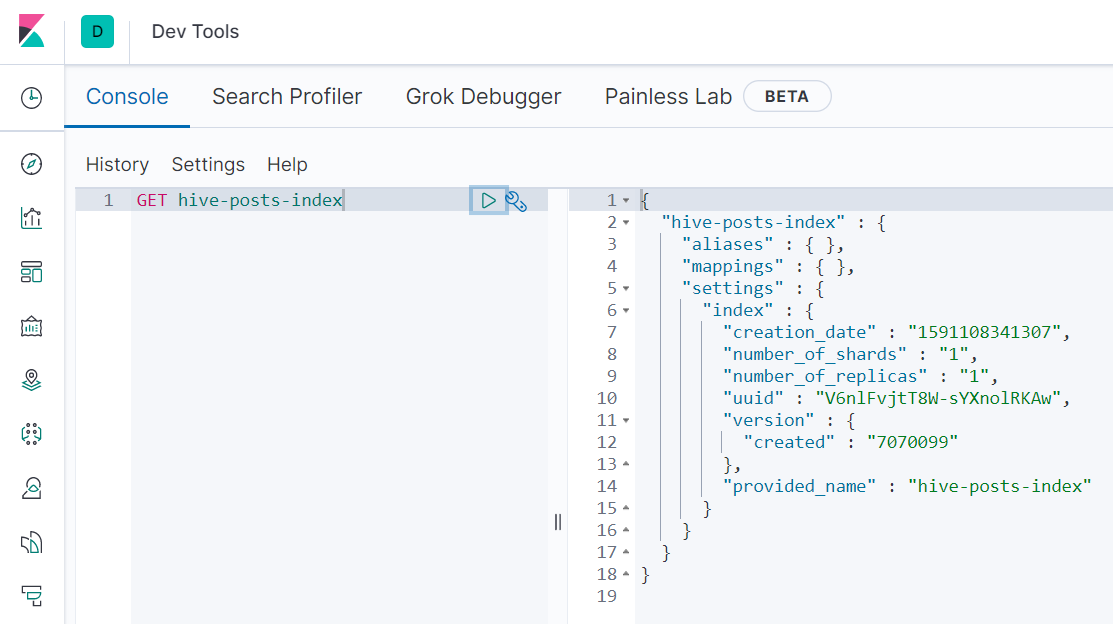
As shown in Kibana devtool, the ES index has been created:
Add a test document into your index:
es.index(index="hive-posts-index", id=1, body={"any": "data", "timestamp": datetime.now()})
Read the document you just added from ES:
>>> es.get(index="hive-posts-index", id=1)
{'_index': 'hive-posts-index', '_type': '_doc', '_id': '1', '_version': 1, '_seq_no': 0, '_primary_term': 1, 'found': True, '_source': {'any': 'data', 'timestamp': '2020-06-02T15:52:40.759337'}}
Add Hive posts into ES index
Here is a demo script to add my latest 5 posts into ES index:
from beem import Steem
from beem.account import Account
from datetime import datetime
from elasticsearch import Elasticsearch
es = Elasticsearch()
hive = Steem(nodes = 'https://api.hive.blog')
account = Account('aafeng', steem_instance = hive)
posts = account.get_blog(start_entry_id=0, limit=5)
for post in posts:
author = post.author
title = post.title
body = post.body
category = post.category
permlink = post.permlink
es.index(index="hive-posts-index", id=permlink, body={"author": author,\
"title": title,\
"body": body,\
"category": category,\
"permlink": permlink,\
"timestamp": datetime.now()})
We can query it in Kibana:
GET hive-posts-index/_search?q=*:*
The output suggests that my posts have been stored in ES:
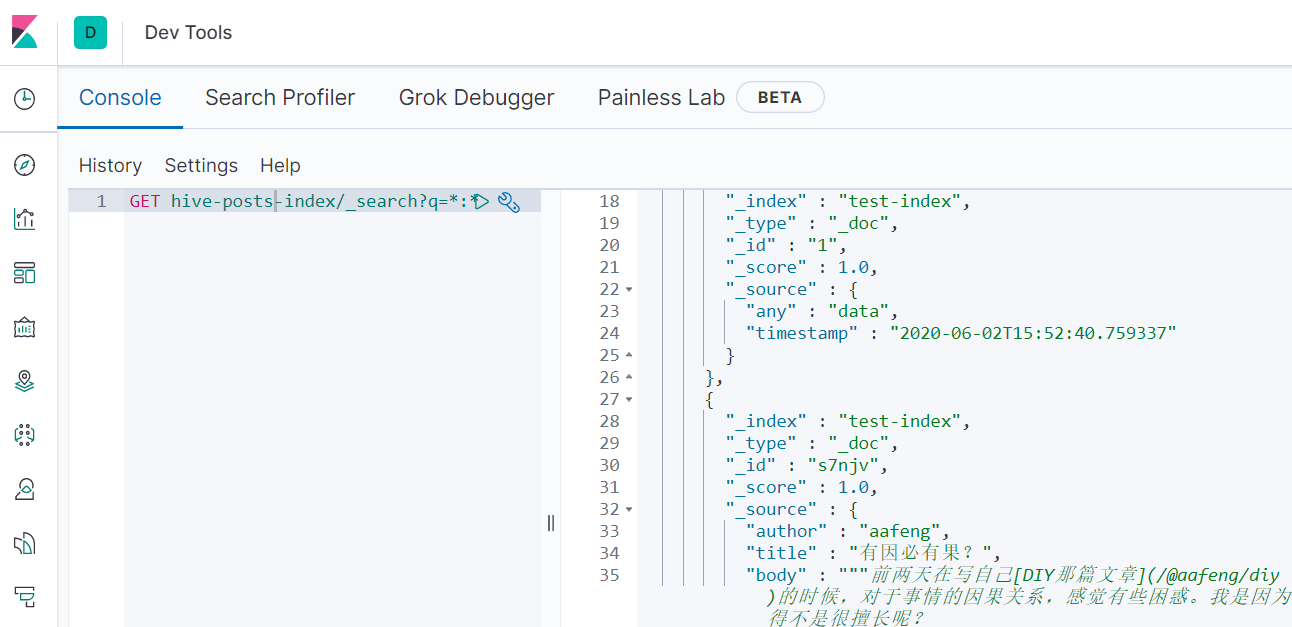
We also can use curl to test if my posts have been saved into ES:
curl http://localhost:9200/hive-posts-index/_search\?size=5
Now we have flexi way to query post data:
GET hive-posts-index/_search?q=body:elasticsearch
GET hive-posts-index/_search?q=category:hive-105017







Comments